
---
---  --- # How does the performance scale with size? --- # Huge tables? --- # Compressibility? If you are sending the filters over a network, you can further compress it.
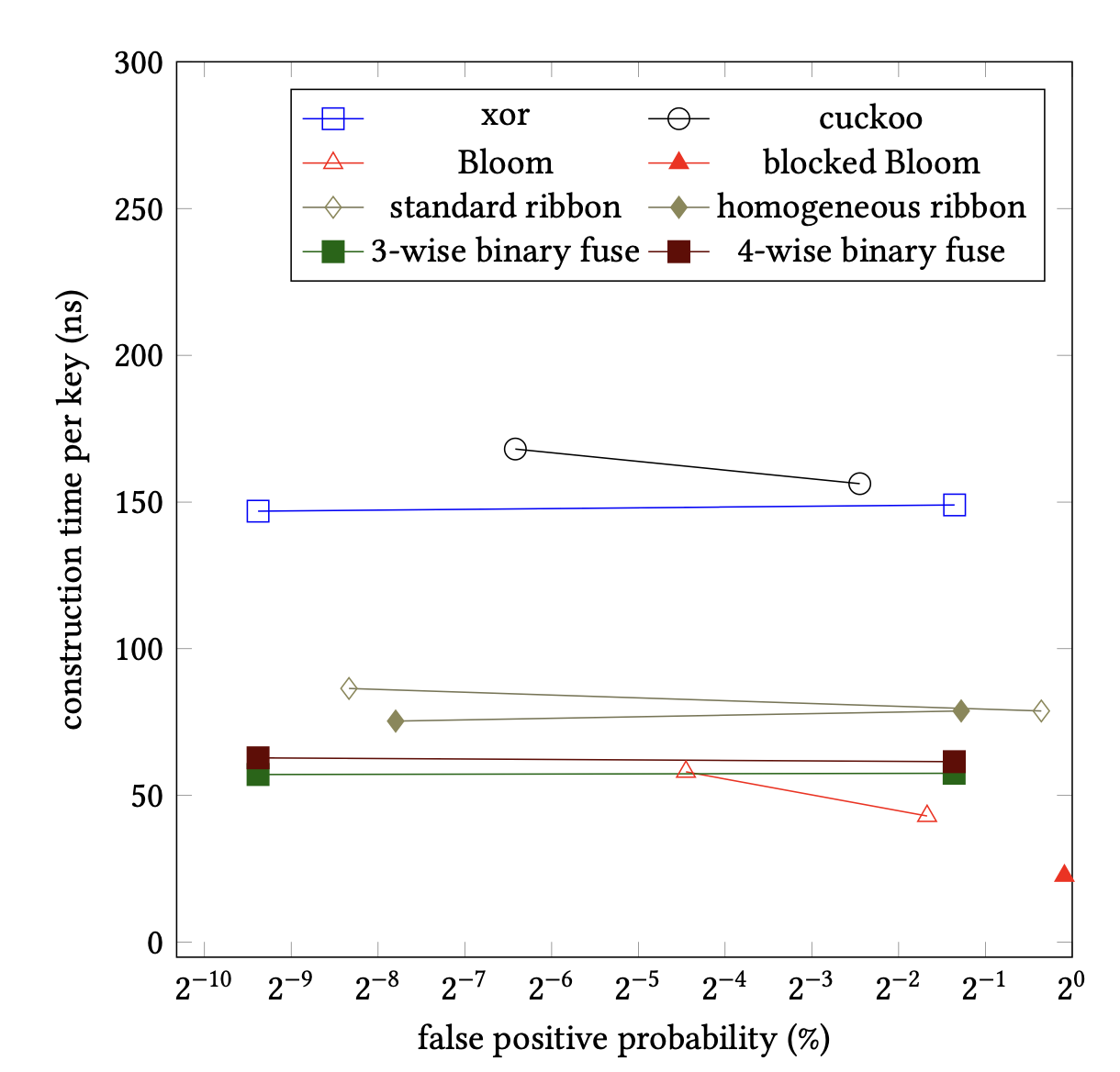
Gap between binary fuse filters and blocked Bloom filters is less. Regular Bloom struggles (lots of computation plus mispredictions).
Block Bloom filters dominate in performance.